Algorithm Classification and Regression Trees (CART)
Classification and Regression Trees (CART) adl salah satu metode / algoritma dari teknik pohon keputusan. CART adl sebuah metode statistik nonparametrik yg dapat menggambarkan hubungan antara variabel respon (variabel dependen) dng satu / lebih variabel prediktor (variabel independen). Menurut Breiman dkk (1993), bila variabel respon berbentuk kontinu maka metode yg dipakai adl metode regresi pohon (regression trees), sedangkan bila variabel respon memiliki skala kategorik maka metode yg dipakai adl metode klasifikasi pohon (classification trees). Variabel respon dalam penelitian ini berskala kategorik, sehingga metode yg akan dipakai adl metode klasifikasi pohon.
Pembentukan pohon klasifikasi terdiri atas 3 tahap yg memerlukan learning sample L. Tahap pertama adl pemilihan pemilah. Setiap pemilahan hanya bergantung pada nilai yg berasal dari satu variabel independen. Untuk variabel independen kontinu Xj dng ruang sampel berukuran n dan terdapat n nilai amatan sampel yg berbeda, maka akan terdapat n - 1 pemilahan yg berbeda. Sedangkan untuk Xj adl variabel kategori nominal bertaraf L , maka akan diperoleh pemilahan sebanyak (2^(L-1)) - 1 . Tetapi jika variabel X୨ adl kategori ordinal maka akan diperoleh L1 pemilahan yg mungkin. Metode pemilahan yg sering dipakai adl indeks Gini dng fungsi sebagai berikut
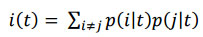
dengan ݅i(t) adl fungsi keheterogenan indeks gini, p(i|t) adl proporsi kelas i pada simpul t, dan p(j|t) adl proporsi kelas j pada simpul t. Goodness of split merupakan sebuah evaluasi pemilahan oleh pemilah s pada simpul t. Goodness of split ∅ (s,t) didefinisikan sebagai penurunan keheterogenan.

Algoritma CART (Classification And Regression Trees)
Pengembangan pohon dilakukan dng mencari semua kemungkinan pemilah pada simpul sehingga ditemukan pemilah s* yg memberikan nilai penurunan keheterogenan tertinggi yaitu,

dengan ∅ (s,t) adl kriteria goodness of split, ܲܲ PLi(tL) adl proporsi pengamatan dari simpul t menuju simpul kiri, dan PRi(tR) adl proporsi pengamatan dari simpul t menuju simpul kanan.
Tahap kedua adl penentuan simpul terminal. Simpul t dapat dijadikan simpul terminal jika tidak terdapat penurunan keheterogenan yg berarti pada pemilahan, hanya terdapat satu pengamatan (n=1) pada tiap simpul anak atau adanya batasan minimum n serta adanya batasan jumlah level / tingkat kedalaman pohon maksimal. Tahap ketiga adl penandaan label tiap simpul terminal berdasar aturan jumlah anggota kelas terbanyak, yaitu:

dengan p(j|t) adl proporsi kelas j pada simpul t, ܰNj(t) adl jumlah pengamatan kelas j pada simpul t, dan N(t) adl jumlah pengamatan pada simpul t. Label kelas simpul terminal t adl 0j yg memberi nilai dugaan kesalahan pengklasifikasian simpul t terbesar.
Proses pembentukan pohon klasifikasi berhenti saat terdapat hanya satu pengamatan dalam tiap simpul anak atau adanya batasan minimum n, semua pengamatan dalam tiap simpul anak identik, dan adanya batasan jumlah level/kedalaman pohon maksimal. Setelah terbentuk pohon maksimal tahap selanjutnya adl pemangkasan pohon untuk mencegah terbentuknya pohon klasifikasi yg berukuran sangat besar dan kompleks, sehingga diperoleh ukuran pohon yg layak berdasarkan cost complexity prunning, maka besarnya resubtitution estimate pohon T pada parameter kompleksitas α yaitu :
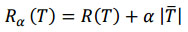 dengan Rα(T) adl resubtitution sebuah pohon T pada kompleksitas α , ܴR(T) adlresubstitution estimate, α adl parameter cost-complexity bagi penambahan satu simpul akhir pada pohon T, dan |ܶT| adl banyaknya simpul terminal pohon T.
dengan Rα(T) adl resubtitution sebuah pohon T pada kompleksitas α , ܴR(T) adlresubstitution estimate, α adl parameter cost-complexity bagi penambahan satu simpul akhir pada pohon T, dan |ܶT| adl banyaknya simpul terminal pohon T.
Cost complexity prunning menentukan pohon bagian ܶT(α) yg meminimumkan Rα(T) pada seluruh pohon bagian untuk setiap nilai α . Nilai parameter kompleksitas α akan secara perlahan meningkat selama proses pemangkasan. Selanjutnya pencarian pohon bagian T(α) < Tmax yang dapat meminimumkan Rα(T) yaitu :
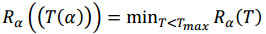
Setelah dilakukan pemangkasan diperoleh pohon klasifikasi optimal yg berukuran sederhana namun memberikan nilai pengganti yg cukup kecil. Penduga pengganti yg sering dipakai adl penduga sampel uji (test sample estimate) dan validasi silang lipat V (Cross Validation V-Fold Estimate)
Algoritma CART (Classification And Regression Trees)

Statistik uji yg dipakai adl sebagai berikut.

Algoritma CART (Classification And Regression Trees)
Pembentukan pohon klasifikasi terdiri atas 3 tahap yg memerlukan learning sample L. Tahap pertama adl pemilihan pemilah. Setiap pemilahan hanya bergantung pada nilai yg berasal dari satu variabel independen. Untuk variabel independen kontinu Xj dng ruang sampel berukuran n dan terdapat n nilai amatan sampel yg berbeda, maka akan terdapat n - 1 pemilahan yg berbeda. Sedangkan untuk Xj adl variabel kategori nominal bertaraf L , maka akan diperoleh pemilahan sebanyak (2^(L-1)) - 1 . Tetapi jika variabel X୨ adl kategori ordinal maka akan diperoleh L1 pemilahan yg mungkin. Metode pemilahan yg sering dipakai adl indeks Gini dng fungsi sebagai berikut
dengan ݅i(t) adl fungsi keheterogenan indeks gini, p(i|t) adl proporsi kelas i pada simpul t, dan p(j|t) adl proporsi kelas j pada simpul t. Goodness of split merupakan sebuah evaluasi pemilahan oleh pemilah s pada simpul t. Goodness of split ∅ (s,t) didefinisikan sebagai penurunan keheterogenan.
Algoritma CART (Classification And Regression Trees)
Pengembangan pohon dilakukan dng mencari semua kemungkinan pemilah pada simpul sehingga ditemukan pemilah s* yg memberikan nilai penurunan keheterogenan tertinggi yaitu,
dengan ∅ (s,t) adl kriteria goodness of split, ܲܲ PLi(tL) adl proporsi pengamatan dari simpul t menuju simpul kiri, dan PRi(tR) adl proporsi pengamatan dari simpul t menuju simpul kanan.
Tahap kedua adl penentuan simpul terminal. Simpul t dapat dijadikan simpul terminal jika tidak terdapat penurunan keheterogenan yg berarti pada pemilahan, hanya terdapat satu pengamatan (n=1) pada tiap simpul anak atau adanya batasan minimum n serta adanya batasan jumlah level / tingkat kedalaman pohon maksimal. Tahap ketiga adl penandaan label tiap simpul terminal berdasar aturan jumlah anggota kelas terbanyak, yaitu:
dengan p(j|t) adl proporsi kelas j pada simpul t, ܰNj(t) adl jumlah pengamatan kelas j pada simpul t, dan N(t) adl jumlah pengamatan pada simpul t. Label kelas simpul terminal t adl 0j yg memberi nilai dugaan kesalahan pengklasifikasian simpul t terbesar.
Proses pembentukan pohon klasifikasi berhenti saat terdapat hanya satu pengamatan dalam tiap simpul anak atau adanya batasan minimum n, semua pengamatan dalam tiap simpul anak identik, dan adanya batasan jumlah level/kedalaman pohon maksimal. Setelah terbentuk pohon maksimal tahap selanjutnya adl pemangkasan pohon untuk mencegah terbentuknya pohon klasifikasi yg berukuran sangat besar dan kompleks, sehingga diperoleh ukuran pohon yg layak berdasarkan cost complexity prunning, maka besarnya resubtitution estimate pohon T pada parameter kompleksitas α yaitu :
Cost complexity prunning menentukan pohon bagian ܶT(α) yg meminimumkan Rα(T) pada seluruh pohon bagian untuk setiap nilai α . Nilai parameter kompleksitas α akan secara perlahan meningkat selama proses pemangkasan. Selanjutnya pencarian pohon bagian T(α) < Tmax yang dapat meminimumkan Rα(T) yaitu :
Setelah dilakukan pemangkasan diperoleh pohon klasifikasi optimal yg berukuran sederhana namun memberikan nilai pengganti yg cukup kecil. Penduga pengganti yg sering dipakai adl penduga sampel uji (test sample estimate) dan validasi silang lipat V (Cross Validation V-Fold Estimate)
Algoritma CART (Classification And Regression Trees)
Uji Sampel Berpasangan
Dalam membandingkan dua perlakuan diperlukan unit eksperimen / subjek yg memiliki kesamaan, sehingga perbedaan pada respon antara kedua grup dapat dihubungkan perbedaannya sebagai perlakuan. Dalam uji perbandingan berpasangan, respon dalam unit eksperimen dipengaruhi oleh kondisi yg terdapat dalam blok dan efek perlakuan. Penelitian ini menggunakan uji hipotesis yang bersifat satu arah dng penjelasan sebagai berikut.Statistik uji yg dipakai adl sebagai berikut.
Algoritma CART (Classification And Regression Trees)
CONTOH PROGRAM
Berikut ini adalah contoh implementasi program sederhana untuk Algoritma CART (Classification And Regression Trees) dengan menggunakan bahasa pemrograman Java.Source Code Java
import java.io.File;
import java.io.FileOutputStream;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import rs.fon.whibo.GDT.algorithm.GDTAlgorithm;
import rs.fon.whibo.GDT.problem.GenericTreeProblemBuilder;
import rs.fon.whibo.integration.adapters.parameter.ParameterTypeProblemFile;
import rs.fon.whibo.integration.adapters.parameter.ProblemFileValueEditor;
import rs.fon.whibo.problem.Problem;
import rs.fon.whibo.problem.serialization.ProblemDecoder;
import com.rapidminer.example.ExampleSet;
import com.rapidminer.gui.properties.PropertyTable;
import com.rapidminer.operator.OperatorDescription;
import com.rapidminer.operator.OperatorException;
import com.rapidminer.operator.learner.AbstractLearner;
import com.rapidminer.operator.learner.LearnerCapability;
import com.rapidminer.operator.learner.tree.Tree;
import com.rapidminer.operator.learner.tree.TreeModel;
import com.rapidminer.parameter.ParameterType;
import com.rapidminer.parameter.ParameterTypeDouble;
import com.rapidminer.parameter.ParameterTypeInt;
public class CART extends AbstractLearner {
protected static String PROBLEM_FILE = "problem file";
public static final String PARAMETER_MAX_TREE_DEPTH = "max_tree_depth";
public static final String PARAMETER_MIN_NODE_SIZE = "min_node_size";
public static final String PARAMETER_MIN_LEAF_SIZE = "min_leaf_size";
public static final String PARAMETER_PRUNNING_SEVERITY = "prunning_severity";
public CART(OperatorDescription description) {
super(description);
PropertyTable.registerPropertyValueCellEditor(ParameterTypeProblemFile.class, ProblemFileValueEditor.class);
}
@Override
public List<ParameterType> getParameterTypes() {
List<ParameterType> types = super.getParameterTypes();
ParameterType type = new ParameterTypeProblemFile(getProblemFile(),
"Process file from which to load the generic tree", "wba",
false, GenericTreeProblemBuilder.class);
type.setDefaultValue("C:\\WhiBoHCI\\Algorithms\\CART.wba");
type.setExpert(true);
type.setHidden(true);
types.add(type);
type = new ParameterTypeInt(PARAMETER_MAX_TREE_DEPTH, "The maximal tree depth of a leaf node.", 1, 10000, 10000);
type.setExpert(false);
types.add(type);
type = new ParameterTypeInt(PARAMETER_MIN_NODE_SIZE, "The minimal number of instances in a node.", 1, 100000, 1);
type.setExpert(false);
types.add(type);
type = new ParameterTypeInt(PARAMETER_MIN_LEAF_SIZE, "The minimal number of instances in a leaf node to be left after prunning.", 1, 100000, 1);
type.setExpert(false);
types.add(type);
type = new ParameterTypeDouble(PARAMETER_PRUNNING_SEVERITY, "The severity of the prune proces. Greater value means more prunning and smaller resulting tree.", 0.0001, 0.5, 0.0001);
type.setExpert(false);
types.add(type);
return types;
}
@Override
public TreeModel learn(ExampleSet exampleSet) throws OperatorException {
modifyXML();
String fileLocation = getParameterAsString(getProblemFile());
File file = new File(fileLocation);
Problem process = ProblemDecoder.decodeFromXMLToProces(file.getAbsolutePath());
TreeModel model;
try{
GDTAlgorithm builder = new GDTAlgorithm(process);
Tree root = builder.learnTree(exampleSet);
model = new TreeModel(exampleSet, root);
return model;
}catch(Exception e){
throw new OperatorException(e.getMessage(),e);
}
}
@Override
public boolean supportsCapability(LearnerCapability capability) {
if (capability == com.rapidminer.operator.learner.LearnerCapability.BINOMINAL_ATTRIBUTES)
return true;
if (capability == com.rapidminer.operator.learner.LearnerCapability.POLYNOMINAL_ATTRIBUTES)
return true;
if (capability == com.rapidminer.operator.learner.LearnerCapability.NUMERICAL_ATTRIBUTES)
return true;
if (capability == com.rapidminer.operator.learner.LearnerCapability.POLYNOMINAL_CLASS)
return true;
if (capability == com.rapidminer.operator.learner.LearnerCapability.BINOMINAL_CLASS)
return true;
if (capability == com.rapidminer.operator.learner.LearnerCapability.WEIGHTED_EXAMPLES)
return true;
if (capability == com.rapidminer.operator.learner.LearnerCapability.NUMERICAL_CLASS)
return true;
return false;
}
public String getProblemFile() {
return PROBLEM_FILE;
}
public void setProblemFile(String pf) {
PROBLEM_FILE = pf;
}
public Class<?>[] getOutputClasses() {
return new Class[] { TreeModel.class };
}
private void modifyXML() throws OperatorException{
String fileLocation = getParameterAsString(getProblemFile());
int treeDepth = getParameterAsInt(PARAMETER_MAX_TREE_DEPTH);
int minNodeSize = getParameterAsInt(PARAMETER_MIN_NODE_SIZE);
int minLeafSize = getParameterAsInt(PARAMETER_MIN_LEAF_SIZE);
double prunningSeverity = getParameterAsDouble(PARAMETER_PRUNNING_SEVERITY);
setXMLParameter(fileLocation, "Tree_Depth", String.valueOf(treeDepth));
setXMLParameter(fileLocation, "Size", String.valueOf(minNodeSize));
setXMLParameter(fileLocation, "Size_Of_Leaf", String.valueOf(minLeafSize));
setXMLParameter(fileLocation, "Confidence_Level", String.valueOf(prunningSeverity));
}
private void setXMLParameter(String xmlFileLocation, String parameterName, String newValue) throws OperatorException{
DocumentBuilderFactory docFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder docBuilder;
Document doc;
try {
docBuilder = docFactory.newDocumentBuilder();
doc = docBuilder.parse(xmlFileLocation);
NodeList list = doc.getElementsByTagName("void");
Node node;
Node parameterNode;
int end = list.getLength();
for (int i = 0; i < end; i++){
node = list.item(i);
if (node.getAttributes().item(0).getNodeValue().equals("nameOfParameter")){
if (node.getChildNodes().item(1).getFirstChild().getNodeValue().equals(parameterName)){
node = list.item(i+2);
parameterNode = node.getChildNodes().item(1).getFirstChild();
parameterNode.setNodeValue(newValue);
}
}
}
Transformer transformer = TransformerFactory.newInstance().newTransformer();
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
DOMSource source = new DOMSource(doc);
transformer.transform(source, new StreamResult(new FileOutputStream(xmlFileLocation)));
} catch (Exception e) {
throw new OperatorException("Error working with xml file");
}
}
}

ok bray
BalasHapussiap gan~
Hapusnice gan
BalasHapusMksih sis~
HapusNice info
BalasHapus(eric)
Thanks gan~
Hapus